



Ricordate che di recente avevo scritto una guida sulla gestione di base del database MySQL?
Bene. Oggi vorrei approfondire questo argomento con voi, aggiungendo alcune nuove nozioni per una gestione più avanzata, di quella che avevamo visto in precedenza, del database.
Per iniziare questo argomento, per prima cosa dobbiamo introdurre una struttura logia, necessaria per riuscire a comprendere al meglio come si deve effettuare un buon database.
Per farlo occorrerà o carta e penna, oppure, dato che sicuramente starai lavorando al computer, la piattaforma draw.io
E’ possibile volendo utilizzare un qualsiasi altro software di progettazione. L’importante è che abbia tutte le figure geometriche necessarie per rappresentare Flow Chart, diagrammi UML e Diagrammi ER.
Ho evidenziato i diagrammi ER perché sono i diagrammi che ci interessano a noi. ER -> entità relazione, è una tipologia di linguaggio logico, grafico e ad oggetti per riuscire a comprendere come realizzare le tabelle di un database al meglio, per ottimizzare il proprio progetto e renderlo più efficiente.
La parte logica della progettazione del database è la fase più difficile, lunga e impegnativa, ma che una volta attuata farà risparmiare molto tempo nella creazione del proprio database.
Bene. E’ inutile girarci intorno un’altro po’. Iniziamo.
Un diagramma ER è composto da delle relazioni di entità. Un’entità è un’insieme di aggettivi. Gli aggettivi si definiscono attributi.
Le entità successivamente andranno a formare le tabelle e gli attributi andranno a formare gli attributi esterni.
Nello scorso articolo avevamo visto come era strutturata una tabella.
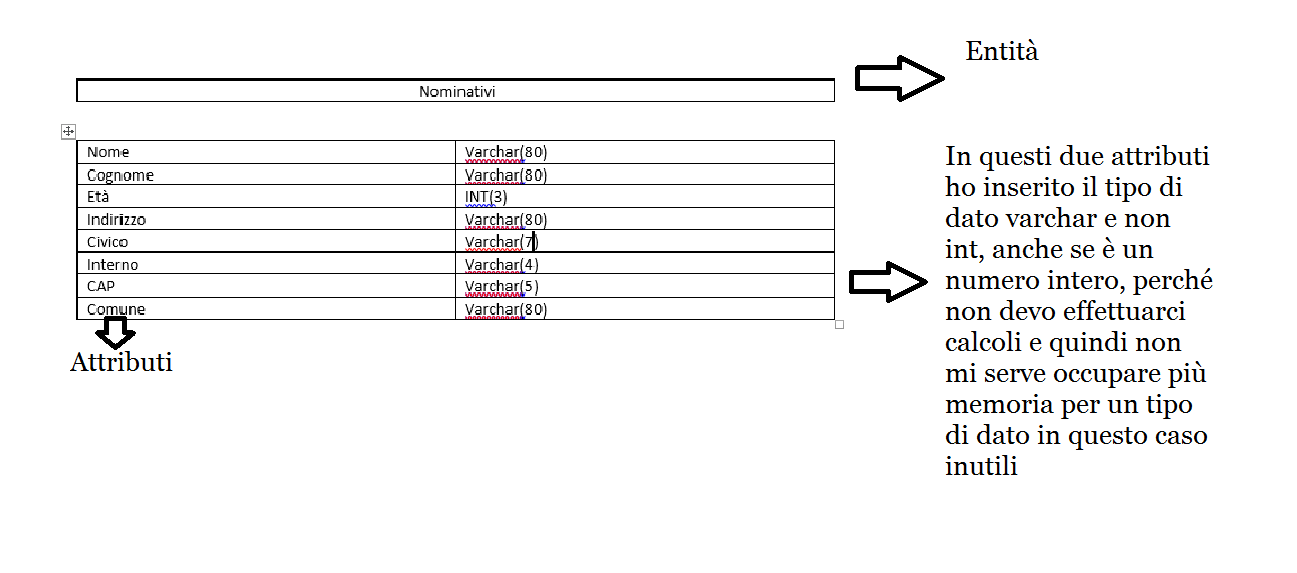
Molto bene. Una volta capito questo, sarà più semplice comprendere il resto.
Vediamo ora un esempio di diagramma ER
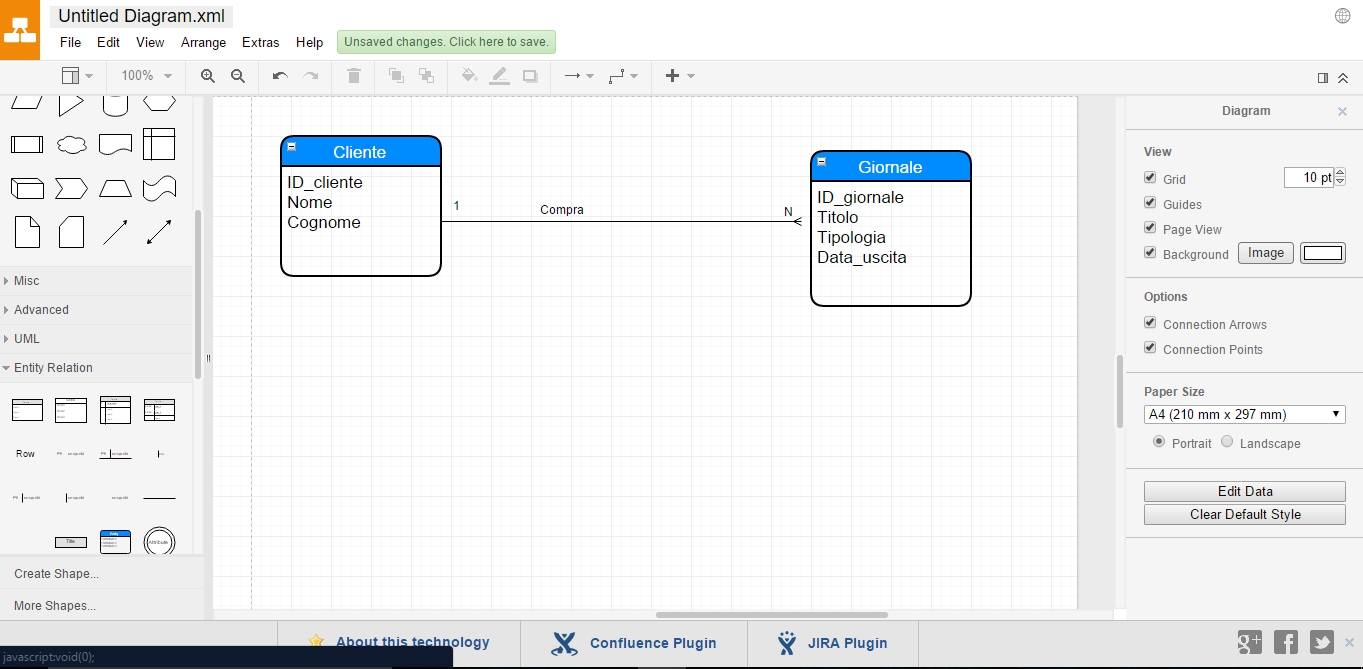
Vediamo di capire bene questo diagramma.
Innanzi tutto noteremo due riquadri. Queste sono le entità. All’interno vi sono presenti tutti i relativi attributi.
Tra le due entità è presente una linea. Questa è una relazione. La relazione presenta un verbo, che in questo caso è compra. Per poter verificare se la relazione è corretta e per capirla al meglio, è necessario scrivere le regole di lettura
Ogni cliente compra uno o più giornali
Ogni giornale viene comprato da un cliente.
E’ importante in ogni regola di lettura utilizzare il termine Ogni. Inoltre in ogni lettura, è necessario leggere in entrambi i sensi della relazione. Quindi da sinistra a destra e da destra a sinistra.
In molti casi, durante la lettura da destra a sinistra, è necessario aggiungere davanti ad ogni, il termine Da.
Questo tipo di diagramma è utile soprattutto con più di due entità.

In questo diagramma ho aggiunto innanzi tutto una relazione e un’entità in più rispetto al precedente. Inoltre ho anche aggiunto un altro tipo di relazione, segnata con il rombo, che serve per specificare altri attributi, come ad esempio anno di recitazione del film, come in questo caso.
Tramite le relazione che abbiamo implementato, è possibile riuscire a collegare in modo logico l’entità film e l’entità attori e quindi potremmo collegare entrambe le tabelle che successivamente andremo a creare.
Più avanti, noterete l’utilità di questa tipologia di schema nella creazione del nostro database.
Vediamo ora le regole di lettura di questo diagramma:
1)
Ogni film viene recitato da uno o più attori
Ad ogni attore recita in un film
2)
Ogni film viene diretto da un regista
Ad ogni regista dirige un film
Bene. Come vedrete, non è difficile interpretare questo tipo di diagramma. Noteremo anche l’utilità delle regole di lettura, che ci permetteranno poi di progettare il database seguendo il progetto logico iniziale.
Lo so che sembra un po’ complicato e lo è per alcuni aspetti. Ma una volta imparato non sarà poi troppo difficile.
Iniziamo ora a scrivere uno schema relazionale in riferimento del diagramma ER.
Uno schema relazionale è molto simile al linguaggio SQL che abbiamo visto nella precedente guida.
Film(ID_film, Titolo, Genere),
Attore(ID_attore, Nome, Cognome, Età, Data_nascita, Ruolo, Film_recitati)
Recita(ID_recita, Anno_recitazione, FK_Nome, FK_cognome, FK_ID_attore, FK_Titolo),
Regista(ID_regista, Nome, Cognome, Film_diretti)
Vediamo alcune cose importanti.
Come dicevo prima, il linguaggio usato nella realizzazione di uno schema relazionale è veramente molto simile al linguaggio SQL.
Allora innanzi tutto abbiamo preso le entità e le abbiamo trascritte in future tabelle. Infatti possiamo notare che il nome di ogni entità è al di fuori delle parentesi tonde.
Gli attributi li abbiamo convertiti in parametri della futura tabella. Nello schema relazionale non si deve specificare il tipo di dato. E’ indifferente.
Infatti all’interno delle parentesi tonde vengono soltanto citati i vari attributi, senza specificare il ruolo e il tipo. Tanto questo schema è soltanto di aiuto a livello logico e non ci servirà per il funzionamento del database.
Noterete che nell’entità “Recitato” ho inserito degli attributi con “FK” davanti. Questo parametro serve per utilizzare lo stesso tipo di valore di un’attributo in un’altra tabella. Lo capiremo poi meglio a livello pratico.
Recitato, come abbiamo potuto vedere dal diagramma relazionale, non è una semplice relazione, come lo era “diretto”, ma è una relazione composta, che diventa, quindi, una vera e propria entità e quindi successivamente una tabella, per permettere di effettuare una ricerca mirata combinando quindi Film e attore.
Ad esempio sarà possibile chiedere al database: Dimmi il film in cui era presente Nicolas Cage” Questo è soltanto un esempio, ovviamente, ma che ci permette di capire che è possibile creare database molto più articolati, di come avevamo visto la scorsa volta.
Bene ora direi che è giunto il momento di iniziare a “sporcarsi le mani” con il codice a livello pratico.
Per prima cosa avviamo XAMPP. Precisamente il modulo Apache e il modulo MySQL.

Poi procediamo ad accedere al database tramite il terminale. Ricordo che il comando è:
mysql -h …. -u …. -p

Una volta aperto mysql, provvederemo ad aprire un database esistente o a crearne uno nuovo.

Ora iniziamo a creare le tabelle, nell’ordine scelto nello schema relazionale.
Creiamo quindi per primo la tabella Film
CREATE TABLE test_film(
-> ID_film INT auto_increment,
-> Titolo varchar(100) NOT NULL,
-> Genere varchar(90) NOT NULL,
-> PRIMARY KEY(ID_film));
Allora notiamo alcuni particolari che nella scorsa volta non ho aggiunto al codice.
Innanzi tutto vediamo NOT NULL. Questo parametro aggiuntivo che si va ad aggiungere ad ogni attributo consente di costringere l’utente a inserire obbligatoriamente un valore all’interno di questo campo. Se ciò non verrà fatto, mysql segnalerà un errore e non permetterà l’invio e la registrazione di nessun dato, finché tutti gli spazi contrassegnati da NOT NULL non saranno riempiti.
Ora vediamo come aggiungere uno o più attributi a questa tabella. Per farlo non ci sarà bisogno di rimuovere la tabella e ricrearla, ma si può modificarla con il comando ALTER TABLE
La scorsa volta avevamo visto, di questo comando, la funzione rename to per cambiare nome a una tabella già creata. Ora vedremo il comando ADD
Questo comando permette di inserire uno o più attributi (chiamati anche record in MySQL) in una tabella già esistente.
Per inserire un attributo la sintassi è questa:
ALTER TABLE nome_tabella ADD data varchar(11),
Per inserire due o più attributi la sintassi è:
ALTER TABLE nome_tabella ADD (data varchar(11), età varchar(44)),
Come potrai notare è che l’unica differenza è che in caso si debbano aggiungere più record, sia sufficiente inserirli tra parentesi tonda e separarli con una virgola.
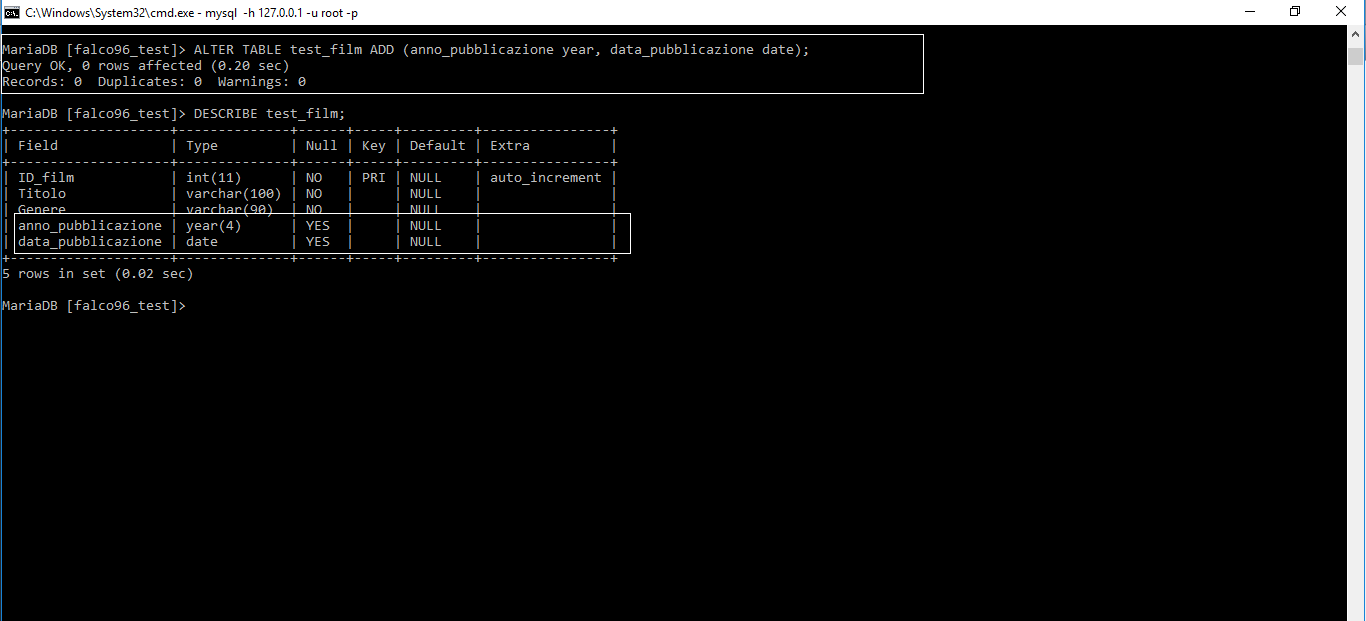
Come potrete notare abbiamo aggiunto 2 record.
Anno_pubblicazione e data_pubblicazione
Data pubblicazione è la data di uscita in sala cinematografica e l’anno di pubblicazione è l’anno in cui è stato reso pubblico il film.
Possiamo notare che abbiamo usato 2 tipi di dato nuovi.
year = è un tipo di dato che permette di creare già uno spazio di 4 caratteri per inserire l’anno.
date = è un tipo di caratteri che crea già un formato apposito per la data. Il formato è: anno/mese/giorno.
Questo tipo di dato permette di effettuare anche dei calcoli per verificare la differenza tra una data e un’altra. Tipo di dato molto comodo e che risparmia molto tempo e molti calcoli.
Procediamo ora a realizzare la tabella Attore
CREATE TABLE Attore(
-> ID_attore INT auto_increment,
-> Nome varchar(90) NOT NULL,
-> Cognome varchar(90) NOT NULL,
-> Età INT(3) NOT NULL,
-> Data_nascita date NOT NULL,
-> Ruolo varchar(90) NOT NULL,
-> Film_recitati varchar(900),
-> PRIMARY KEY(ID_attore));
Qui praticamente non c’è molto da sottolineare. L’unica cosa è Film_recitati. Ho aggiunto la possibilità di aggiungere fino a 900 caratteri, perché in questo record sarà possibile aggiungere i film in cui questo attore ha recitato.
Ma attenzione. Non sarebbe corretto. Sarebbe corretto creare un’entità e quindi una tabella per questo tipo di dato, perché altrimenti il database diventerebbe poco comprensibile. Quindi proviamo ad implementare questa modifica.
Nel nostro schema relazionale
Film(ID_film, Titolo, Genere),
Attore(ID_attore, Nome, Cognome, Età, Data_nascita, Ruolo, Film_recitati),
Regista(ID_regista, Nome, Cognome, Film_diretti),
Rimuoviamo i Film_recitati e la spostiamo in una entità
Film(ID_film, Titolo, Genere),
Attore(ID_attore, Nome, Cognome, Età, Data_nascita, Ruolo),
Recita(ID_recita, FK_ID_attore, titolo_film),
Regista(ID_regista, Nome, Cognome, Film_diretti)
E quindi la modifica da implementare al database sarebbe:
Innanzi tutto rimuovere il record Film_recitati. Per farlo non si dovrà rimuovere la tabella e ricrearla, ma usare la funzione ALTER TABLE con il comando DROP.
Quindi:
ALTER TABLE nome_tabella DROP nome_record;
DROP è un comando che serve per rimuovere record, tabelle o interi database.
Per rimuovere una tabella basterà scrivere:
DROP TABLE nome_tabella;
Per rimuovere un database invece
DROP DATABASE nome_database;

Ora quindi andiamo a realizzare la tabella Recita
CREATE TABLE recita(
-> ID_recita INT auto_increment,
-> ID_attore INT NOT NULL,
-> FOREIGN KEY(ID_attore) REFERENCES attore (ID_attore),
-> titolo_film varchar(90),
-> PRIMARY KEY(ID_recita, ID_attore));
Noterete che abbiamo una nuova istruzione. FOREIGN KEY (o FK) è un comando che serve per gestire e instaurare una relazione tra una tabella e un’altra. In questo caso utilizzeremo la chiave identificativa degli attori per registrare i film prodotti da un tale attore. Volendo potrete aggiungere info come data di pubblicazione, luogo, attori partecipanti e molto altro ancora. Ma questo lo lascio a voi e alla vostra fantasia.
REFERENCES è un comando dell’istruzione FOREIGN KEY e serve per specificare la tabella con cui instaurare la relazione, specificando anche il record specifico (tra parentesi).

Ora procediamo con la creazione della tabella regista
CREATE TABLE regista(
-> ID_regista INT auto_increment,
-> Nome_regista varchar(90),
-> Cognome_regista varchar(90) NOT NULL,
-> Film_diretti varchar(90) NOT NULL,
-> PRIMARY KEY(ID_regista));
Volendo sarà possibile creare un’entità apposita per i film_diretti.

Inseriamo dei dati all’interno delle tabelle

Bene. Come possiamo notare il database funziona correttamente. Noteremo che grazie alla tabella recita è possibile associare l’id dell’utente con l’id dell’attore, per sapere in quanti e in quali film ha recitato. La funzione FOREIGN KEY è molto utile anche per effettuare ricerche avanzate all’interno del database, perché con un’unica ricerca è possibile trovare il nome dell’attore e tutti i film che ha creato.
Bene. Direi che per oggi è tutto da questa guida. Ci ho messo davvero tanto per realizzarla, ma ne è valsa la pensa, per aggiungere nuovi concetti e approfondire quelli già visti nella guida precedente.
Con questo è tutto. Alla prossima!
{kind=link}