



Pochi giorni, fa scrissi un articolo in cui mostravo il modo di installare un server virtuale per recuperare un computer obsoleto.
Nella guida avevo usato il software XAMPP, uno delle piattaforme a mio avviso migliori, per poter sperimentare in locale alcune tecniche di programmazione lato server oppure, come nel caso dell’articolo, di trasformare il proprio computer in un piccolo gestore di file in remoto.
Avevamo visto come gestire i file, le cartelle, gli utenti e i permessi di scrittura associate a queste ultimi.
Avevamo anche dato un’accenno e una breve spiegazione ai vari moduli, tra cui MySQL.
In questo articolo vorrei approfondire questo modulo, spiegando come si gestisce un database a mano per inserire dei dati, che poi potranno essere usati da applicativi in php o semplicemente archiviare dati importanti.
Il database MySQL è in grado di organizzare in modo autonomo i dati all’interno di colonne. E’ in grado di selezionare il dato richiesto senza alcuna difficoltà e con assoluta precisione. La precisione dipende però dalla bravura che il gestore del database ha nel strutturare bene i dati da memorizzare.
MySQL è un vero e proprio server. Questo server viene gestito da un DBMS -> Database Management System.
Questo strumento, che è il gestore vero e proprio del server, si prende carico dei dati e fa in modo di consentirne l’accesso agli utenti autorizzati in modo semplicissimo e in tempi praticamente immediati.
Quindi se si necessita di gestire grandi o piccole quantità di dati, non sarà un problema e sicuramente è molto meglio di Excel.
L’intento di questo articolo è mostrarti che un database non serve soltanto a gestire CMS come WordPress, ma può fare molto di più.
Ora possiamo iniziare a vedere alcune caratteristiche di MySQL.
Comunicazione
La comunicazione con il proprio database è molto importante. E’ possibile instaurare una comunicazione anche in remoto da un database ad un altro, a patto che siano nella stessa rete, ovvero collegati allo stesso modem/router o qualsiasi altro sistema di connessione.
Questo fa in modo che ci riagganciamo al precedente articolo, postato in precedenza. E’ possibile riciclare per davvero un computer obsoleto, trasformandolo in un server e comandarlo a distanza, inserendo gli eventuali dati o impartendo i comandi necessari da un’altro dispositivo, come si fa normalmente su un hosting o server online, situato magari dall’altra parte del mondo. Il nostro però sarà un sistema casalingo, ma che può offrire vantaggi che non sono da poco.
Questo sistema potrà essere tranquillamente adottato anche su una macchina moderna, se si vogliono ottenere prestazioni veramente vantaggiose.
Ma non mi perdo, per ora, in questi dettagli, altrimenti questo articolo sarà veramente lungo.
Per comunicare con il database di un altro computer, sarà necessario installare XAMPP anche sul computer che useremo per impartire i comandi. Per semplificare questo concetto, prendiamo questo esempio:
Tu hai 2 computer. Uno vecchio e uno nuovo. Vuoi riutilizzare il computer vecchio per trasformarlo in un piccolo server. E utilizzare il secondo computer, quello nuovo, per impartire i comandi. Per farlo dovrai installare XAMPP, che ti permetterà di lanciare comandi. Come una sorta di telecomando. I dati che invierai verranno memorizzati dal piccolo server (il tuo vecchio computer). Quindi da ambo le parti sarà necessario installare il pacchetto server.

Spero di non aver creato troppa confusione per ora. Se si, scrivetelo pure nei commenti. Così potrò aiutarvi al meglio.
Per comunicare con il database presente nello stesso computer è molto semplice. Basterà utilizzare nel modo che vedremo dopo l’ip scelto nella configurazione dell’accesso FTP del server.
Ti consiglio di andare a rileggere l’articolo precedente, per sapere nel dettaglio come importare questo indirizzo IP.
Per comunicare invece con un’altro computer, sarà necessario recarsi nel terminale del computer a cui si vuole instaurare la comunicazione, aprire un terminale e digitare:
ipconfig -> Comando per Windows
ifconfig -> Comando per Linux
E prelevare l’indirizzo IPv4

Sarà inoltre necessario che tutte i moduli delle varie installazioni di XAMPP che verranno coinvolti siano attivi.
Quelli che ci interessano sono: il modulo Apache e il modulo MySQL

Bene. Dopo aver visto tutti questi piccoli passaggi e queste cose teoriche, direi che possiamo procedere con la connessione.
Possiamo iniziare ad aprire il terminale. Lo so, non è certo uno strumento che possa essere molto gradito, ma ti posso assicurare che è molto utile. Sia quello di Windows, che quello di Linux.
Dobbiamo aprire la cartella mysql/bin dal terminale. Per questo digitiamo:
Nel caso di Linux, dato che XAMPP viene installato nella cartella opt, bisognerà digitare:
cd /opt/xampp/mysql/bin/
Su Windows, XAMPP viene installato in c:\xampp, quindi dovremmo digitare:
cd c:\xampp/mysql/bin/
Da adesso in avanti, i comandi da digitare saranno uguali sia su Linux, che su Windows.
Dobbiamo procedere a richiamare il database e a connetterci. Per farlo digitiamo:
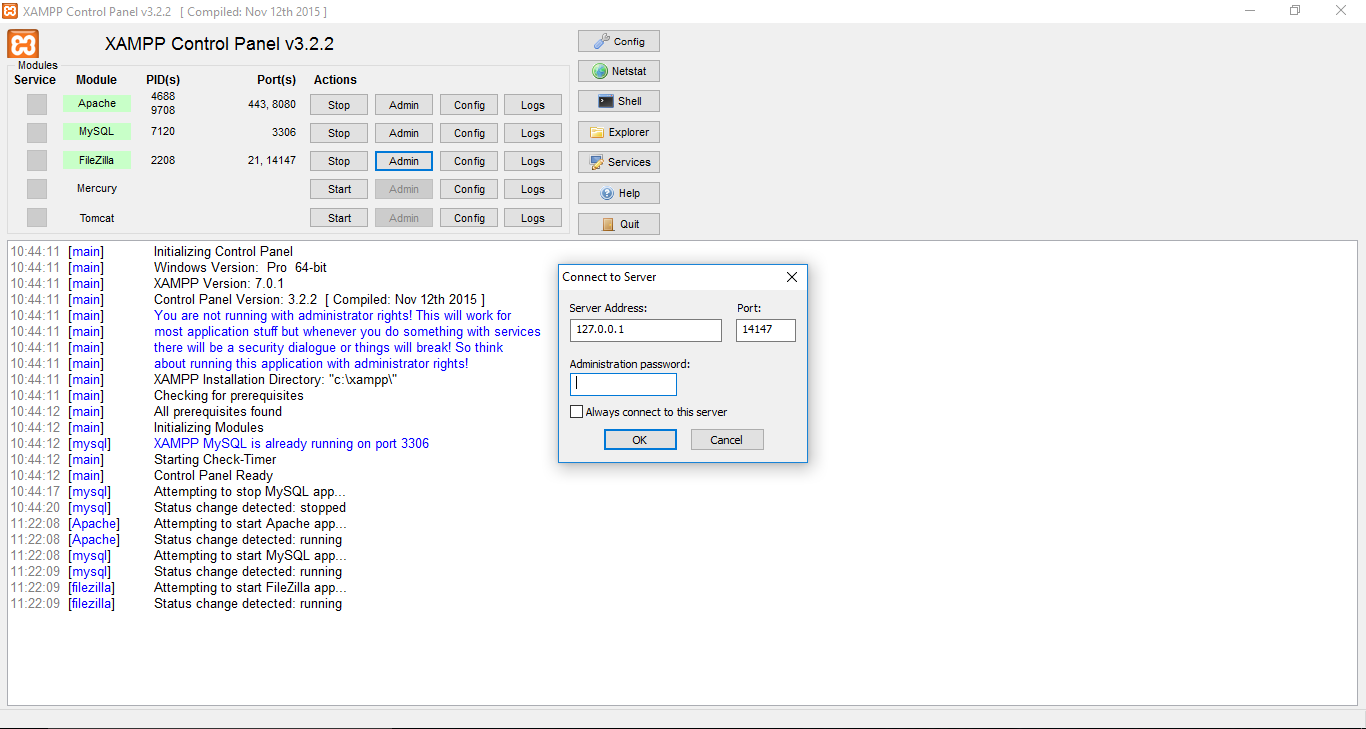
mysql -h indirizzo_ip -u nome_utente -p
Sostituiamo ad indirizzo_ip il nostro indirizzo IP. Ricordiamoci che se vogliamo comunicare con il database contenuto nello stesso computer in cui effettuiamo la comunicazione, bisognerà inserire l’indirizzo IP scelto durante durante la configurazione dell’ftp. Se non avrete modificato il parametro e lasciato l’indirizzo IP originale di default consigliato da XAMPP, l’indirizzo sarà: 127.0.0.1.
Se invece il database con cui vogliamo comunicare non è installato sul computer da cui effettuiamo la comunicazione, l’IP sarà da recuperare con il comando ipconfig o ifconfig (a seconda del sistema operativo usato) e usato l’IP IPV4.
Al posto di nome_utente dovrete inserire il nome utente per accedere al database. Dato che non abbiamo ancora visto come creare utenti, useremo l’utente di default, chiamato root.
Dopo aver premuto invio sul comando e tutto è andato a buon fine, dovremmo ottene questo:

Ora ci richiederà di inserire una password di accesso. Dato che l’utente root, non possiede alcuna password, potrete premere invio direttamente.
Se tutto è andato a buon fine, dovrete visualizzare questo:

La prima cosa che fa un qualsiasi utente su un servizio che non conosce, è richiedere un manuale d’uso.
Per farlo dovrete digitare help;
Il punto e virgola è fondamentale in ogni comando che si lancia. Altrimenti il comando non verrà mai eseguito e il database resterà in attesa.

Apriamo una piccola curiosità. Come potremmo notare, il database usato è MariaDB.

Ti potrai domandare: Ma come, non stavo usando MySQL? La risposta è un si e un no. MySQL fu prodotto originariamente dalla SUN, insieme a una miriade di altri applicativi o interi linguaggi, come JAVA, Virtualbox, OpenOffice e molto altro.
Quando nel 2010 la comprò Oracle, prese possesso di tutti questi brevetti. Oracle si prese carico di questi prodotti. Ma dato che molti dei quali non seguirono lo sviluppo originale, come OpenOffice, MySQL, un team di sviluppatori ex sun presero parte di uno sviluppo di un fork. Così presero vita Libreoffice e MariaDB e una moltitudine di altri tools e linguaggi.
MariaDB è compatibile al 100% con MySQL, e dato che è divenuto un progetto così importante e completo, che piattaforme come WordPress nel giro di qualche anno cambieranno piattaforma e si trasferiranno su database MariaDB.
Interessante vero?
Ritorniamo al database. La guida che abbiamo richiamato cambia e varia, aggiungendo comandi utili a seconda della sezione del database a cui stiamo lavorando.
All’interno di un database possono essere contenuti più database. In ogni database è possibile installare o memorizzare tutti i dati necessari.
Per visualizzare i database disponibili, si può lanciare il comando SHOW DATABASES;
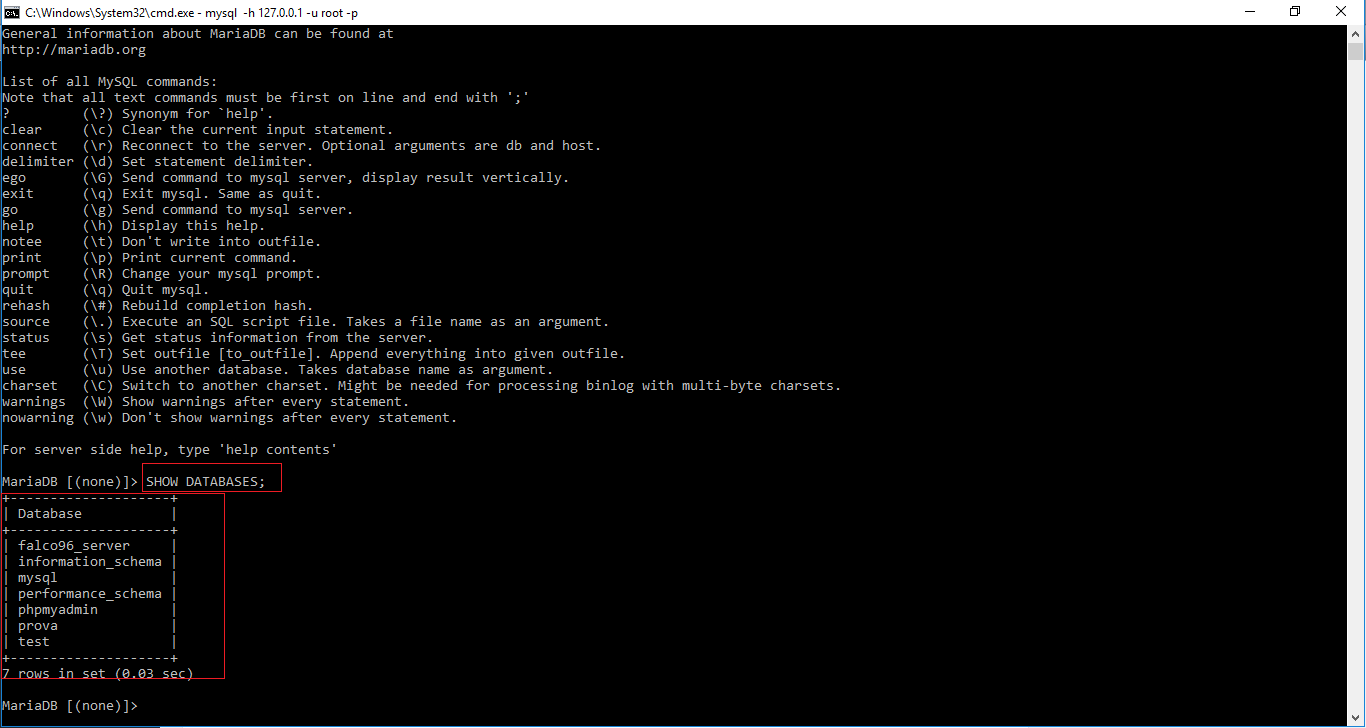
Vi faccio notare un paio di cose. Innanzi tutto la sintassi è molto rigorosa tra maiuscole e minuscole. Un po’ come Linux. La seconda è che i comandi del database sono prevalentemente in Inglese, non c’è nulla di molto complicato. Una volta imparato quei comandi necessari, sarà tutto molto semplice. Praticamente è come impartire piccoli ordini in inglese.
La seconda cosa è che ad ogni richiesta, come questa appena data, che in inglese si dice query, viene mostrato il tempo di risposta, ovvero il tempo che il database ha impiegato per fornirvi una risposta. Questo perché il database è uno strumento veramente preciso, e la sua precisione è utilissima in moltissimi casi. Diciamo in tutti.
Sarà possibile utilizzare tutti i database che si desiderano e crearne anche altri, come vedremo tra poco. Ma attenzione. In un hosting voi avrete un numero di database contati e non potrete crearli con i comandi da shell, ma da interfaccia grafica del vostro hosting. Soltanto in un server dedicato potrete permettervi di creare un numero infinito di database.
Ma sarà possibile creare in remoto delle tabelle e delle colonne, come vedremo dopo.
Dato che con XAMPP avremo un server praticamente dedicato, vediamo come creare un database.
Si utilizza il comando: CREATE DATABASE nome_database;
Io creerò il database falco96_test

Creazione avvenuta con successa. Come vediamo ci segnala che tutto è andato a buon fine. Se si sbaglia sintassi del comando, darà un errore con un determinato codice, che varia a seconda del tipo di errore.
Per verificare se il database è stato creato è possibile rilanciare il comando: SHOW DATABASES;

Se ci sbagliamo e creiamo un database di troppo o comunque non ci serve più un database, è possibile rimuoverlo con il comando:
DROP DATABASE nome_database.
Bene. Ora, per usare un database, dobbiamo lanciare il comando:
USE nome_database;
Al posto di nome_database, dovremmo fornire il nome del database che si desidera usare.
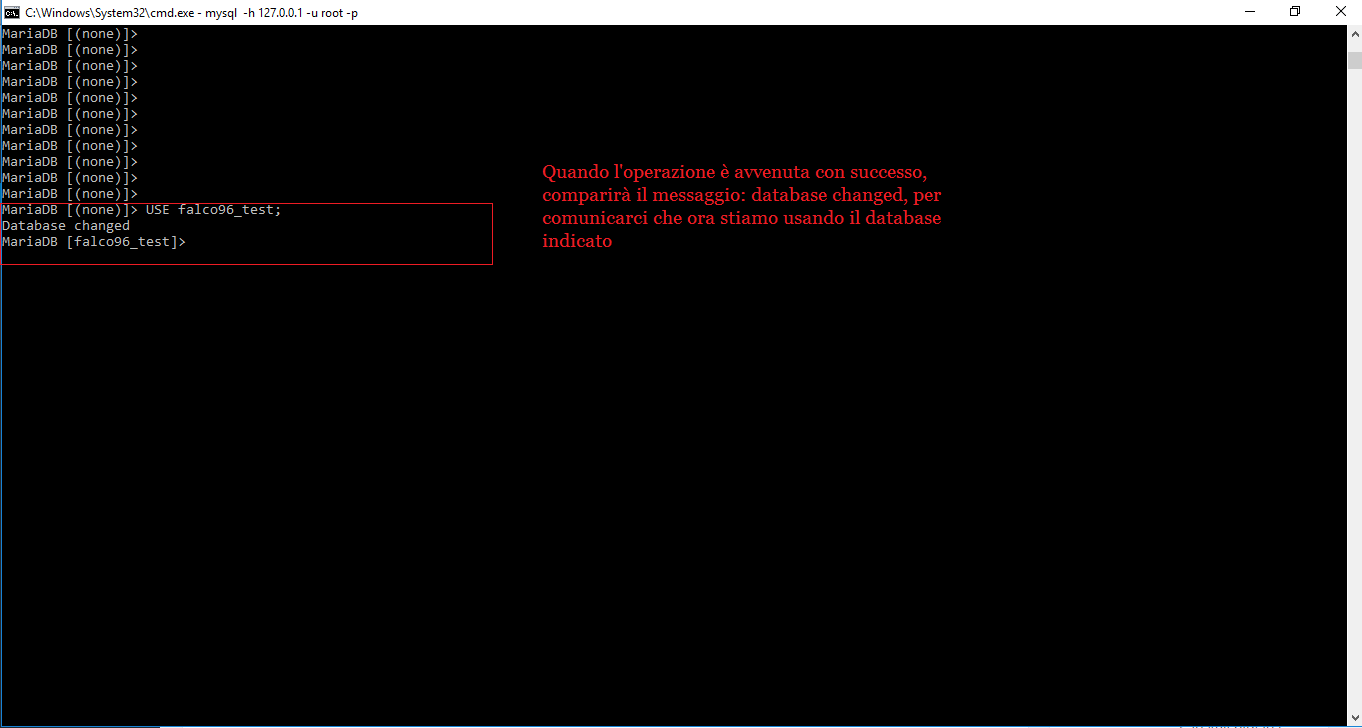
Ora siamo entrati all’interno del database. All’interno possiamo inserire delle tabelle, che conterranno i vari dati. Le tabelle vengono suddivise in due sezioni. La prima specifica il nome delle varie colonne (ad esempio nome giocatore, oggetti ecc…), specifica il tipo di dato contenuto nella tabella e altre informazioni. La seconda parte della tabella contiene i dati che si andranno ad inserire.
Una tabella è dinamica. E’ possibile inserire quanti dati si vogliono. Sarà poi il DBMS a prendersi il carico della gestione.
Dati in un database
Perché un database funzioni correttamente, ci sono diverse regole da rispettare. Se questo tipo di metodologia di inserimento e di formazione del database non viene rispettata, si verificano dei problemi a lungo termine.
I problemi possono essere principalmente di inconsistenza.
Un problema di inconsistenza è derivato dal fatto che 2 o più dati sono uguali o hanno minime variazioni.
ES:
nome: falco96 sito: www.falco96.com
dato 2
nome: falco96 sito: www.falco96,it
Il database non sa quale dato scegliere perché non capisce quale sia quello corretto.
Questo problema potrebbe causare errori gravissimi, che si possono evitare in modo piuttosto facile.
Per risolvere il problema infatti, si utilizza una chiave univoca, che serve per riconoscere tutti i dati. Anche se i dati saranno uguali, risulteranno differenti dal database grazie alla chiave univoca. Vedremo dopo come impostare il tutto.
I tipi di dati
Abbiamo prima accennato al fatto che nelle tabelle è presente anche il tipo di dato. In questo articolo vedremo i più usati: INT e varchar.
INT: è un dato numerico di tipo intero. Con questo tipo di dato sarà possibile effettuare calcoli ed eseguire operazioni su tutti i dati di valore numerico
varchar: E’ un dato di tipo stringa. Questo dato consente di memorizzare parole, frasi, lettere ecc… Non è possibile effettuare operazioni matematiche su di esse.
I tipi di dato su MySQL rispecchiano il concetto delle variabili, che abbiamo già visto in Java.
Creazione di una tabella
All’interno del database appena creato non è presente alcuna tabella. Sarà necessario crearne una.
Per farlo useremo il comando CREATE TABLE
Ora vedremo di realizzare una tabella che contenga:
un ID unico, uno spazio per inserire un nome, un cognome, uno per l’età
Vediamo insieme come fare:
CREATE TABLE nome_tablella(
id INT auto_increment,
nome varchar(80),
cognome varchar(80),
età INT(3),
PRIMARY KEY(id));
auto_increment = questa opzione serve per permettere di incrementare di 1 il valore di id.
E’ utile perché non dovremmo preoccuparci di gestire l’identificativo di ogni colonna inserita.
Potremmo notare che dopo ogni tipo di dato (ad esempio varchar) è presente un numero tra parentesi. Questo valore numerico non è altro che il massimo numero di caratteri che è possibile inserire.
Nell’attributo id, non è presente alcun limite, in quanto ci penserà auto_increment a gestire il tutto.
Ogni attributo termina con una virgola e non con il punto e virgola. Questo perché il punto e virgola lo si inserisce alla fine di ogni istruzione. Per segnalare invece la presenza di un attributo successivo a quello appena inserito, si inserisce la virgola. Tutti gli attributi sono contenuti tra una parentesi.
PRIMARY KEY(nome_attributo) = Questo parametro serve per indicare qual’è la chiave univoca principale, da prendere in considerazione. In questo caso noi utilizzeremo l’attributo id, per identificare tutti i vari attributi (o colonne) che andremo ad inserire.
Bene creiamo quindi la tabella e vediamo cosa succede.

Come è possibile notare, la tabella è stata creata correttamente. Al posto di nome_tabella, ho inserito il nome nomi.
Ora se vuoi vedere se la tabella è stata creata correttamente, basterà usare, come per visualizzare i database presenti, il comando SHOW, con la differenza che al posto di SHOW DATABASES; scriveremo SHOW TABLES;

Ora mettiamo conto che si necessita di visualizzare tutti i vari attributi della propria tabella, ovvero quelli inseriti durante la sua creazione. Per farlo useremo il comando: DESCRIBE nome_tabella;

Mettiamo conto che dobbiamo inserire un altro campo, ovvero un altro attributo. Ad esempio indirizzo. Penserai che molto probabilmente ci sia bisogno di cancellare la tabella e ricrearla. No si può aggiungere un altro attributo con un determinato comando.
ALTER TABLE nome_tabella ADD indirizzo varchar(100);
ALTER TABLE = questo è un comando che consente di segnalare al database che si ha intenzione di alterare, modificare la struttura di una tabella
ADD = è un comando che permette di aggiungere un attributo all’interno di una tabella.
Il resto è il nome dell’attributo e la sua descrizione, che abbiamo visto anche prima.

Rieseguendo il comando DESCRIBE è possibile notare la modifica
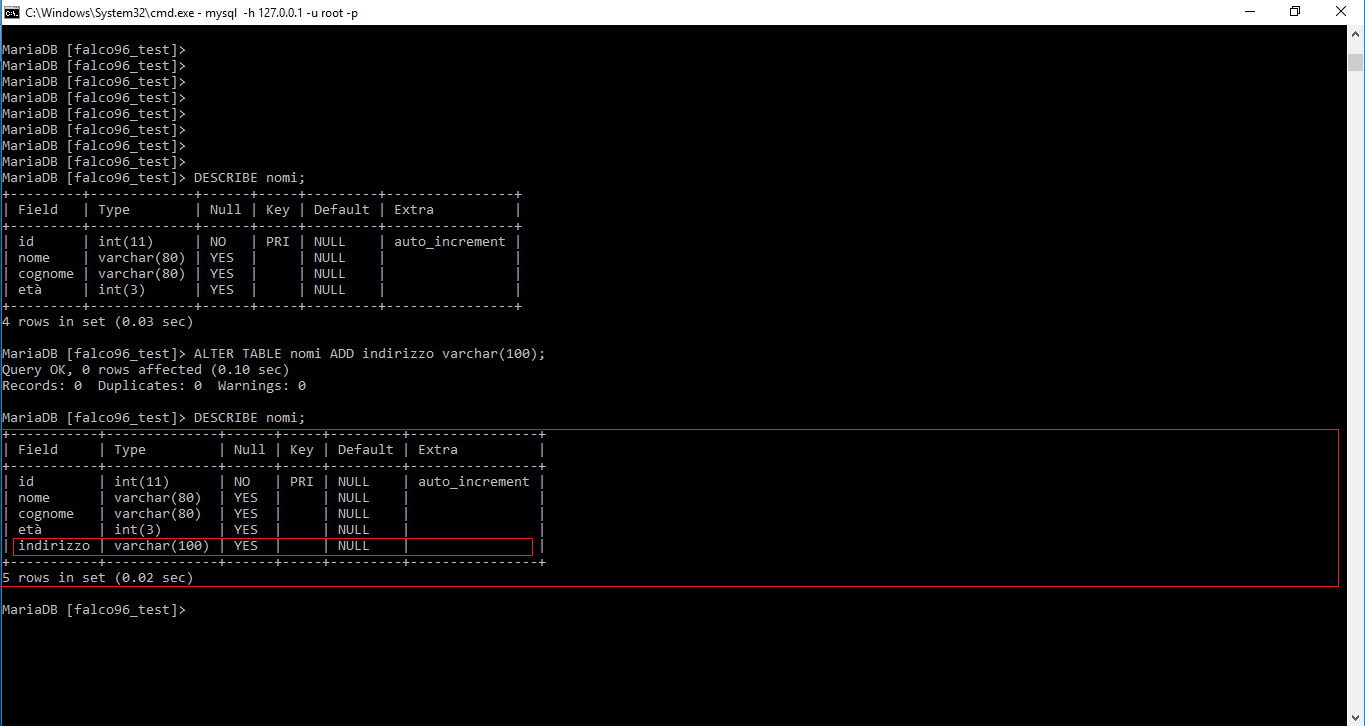
Mettiamo conto che ora dovessimo modificare il nome di una tabella.
Approfondiamo un secondo una cosa. In un qualsiasi hosting è presente un numero limitato di database, se non in alcuni casi un solo database. Quindi in quest’ultimo database si dovranno inserire applicativi, diversi tipi di dati e molto altro ancora. Per poter distinguere quindi le tabelle si utilizza un prefisso, ovvero un nome seguito da un trattino, un po’ come fa WordPress.
Per modificare il nome di una tabella si utilizzerà sempre il comando ALTER TABLE, ma non più il comando ADD, ma rename to
ALTER TABLE nome_tabella rename to nuovo_nome_tabella;
Dove in nome_tabella inseriremo il nome attuale della tabella e al posto di nuovo_nome_tabella il nuovo nome che vogliamo assegnare alla tabella. Non è complicato.

Ora noteremo che se lanciamo il comando SHOW TABLES; il nome della nostra tabella sarà modificato.
Ora andiamo alla parte più interessante, ovvero all’inserimento dei dati all’interno di una tabella:
Per farlo useremo il comando INSERT INTO
INSERT INTO nome_tabella (nomi_attributi) VALUES (“valori”, “attributi”);
Nella prima parentesi tonda ci vorranno i nomi degli attributi. In questo caso, nella nostra tabella è presente l’attributo nome, cognome, età e indirizzo. Poi nella seconda parentesi vanno inseriti i valori da assegnare.
I valori vanno inseriti nello stesso ordine in cui si sono inseriti i nomi degli attributi. Quindi se il primo nome era “nomi” il primo valore corrisponderà al nome.
Quindi:
INSERT INTO nome_tabella (nome, cognome, età, indirizzo) VALUES (“carlo” , “Boschi” , “43” , “Via nord, 55”);
Ogni attributo in entrambe le parentesi è separato da una virgola. I valori sono contenuti tra le virgolette, per segnalare al database che sono appunto dei valori e non dei nomi.

Per comprendere meglio, potrebbe essere utile questo schema

Non sarà lo schema migliore del mondo, dal punto di vista grafico, ma penso che si capisca più che bene.
Ok ora provvediamo ad inserire altri dati, quelli che vogliamo.
Ora per visualizzare i dati è molto semplice. Basterà usare questo comando:
SELECT * FROM nome_tabella;
SELECT = questo comando serve per selezionare uno o più attributi
L’asterisco fa in modo che vengano selezionati tutti i dati presenti nella tabella
FROM = serve per specificare a SELECT dove sono contenuti i dati che si necessitano

Ma qui si vede la praticità del database. Io voglio selezionare un determinato dato, ad esempio di una persona che si chiama “Carlo”. Come fare? Molto semplice
SELECT * FROM nome_tabella WHERE nome_attributo = “valore”;
Traduciamo la sintassi: Seleziona tutti i dati dalla tabella “nome_tabella” dove un determinato attributo ha un determinato valore.
Questa cosa è molto comoda soprattutto quando si hanno con decine di colonne di dati memorizzati.
Posso anche mettere 2 controlli grazie al comando AND
SELECT * FROM nome_tabella WHERE nome_attributo = “valore” AND nome_attributo2 = “valore2”;

Bene. Ora vediamo gli ultimi semplici comandi.
Per prima cosa vediamo come svuotare interamente una tabella da tutti i valori, senza alterare la sua struttura
TRUNCATE nome_tabella;
Questo comando non farà altro che prendere una tabella, rimuoverla e ricrearla uguale, ma senza i valori memorizzati al suo interno.
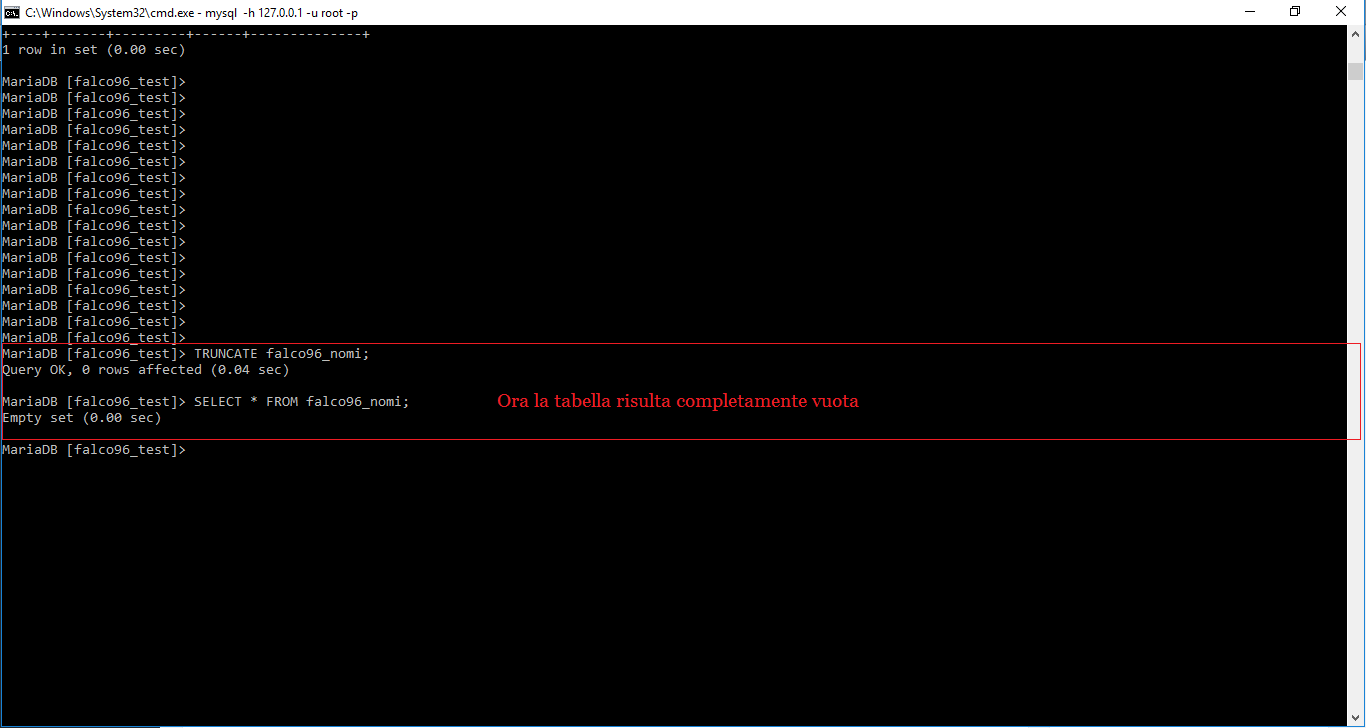
Il secondo comando è molto simile a quello per rimuovere definitivamente un database. Si utilizza sempre DROP.
Al posto di scrivere
DROP DATABASE nome_database;
per rimuover un database, scriviamo:
DROP TABLE nome_tabella;
Per rimuovere una tabella.
Infatti:
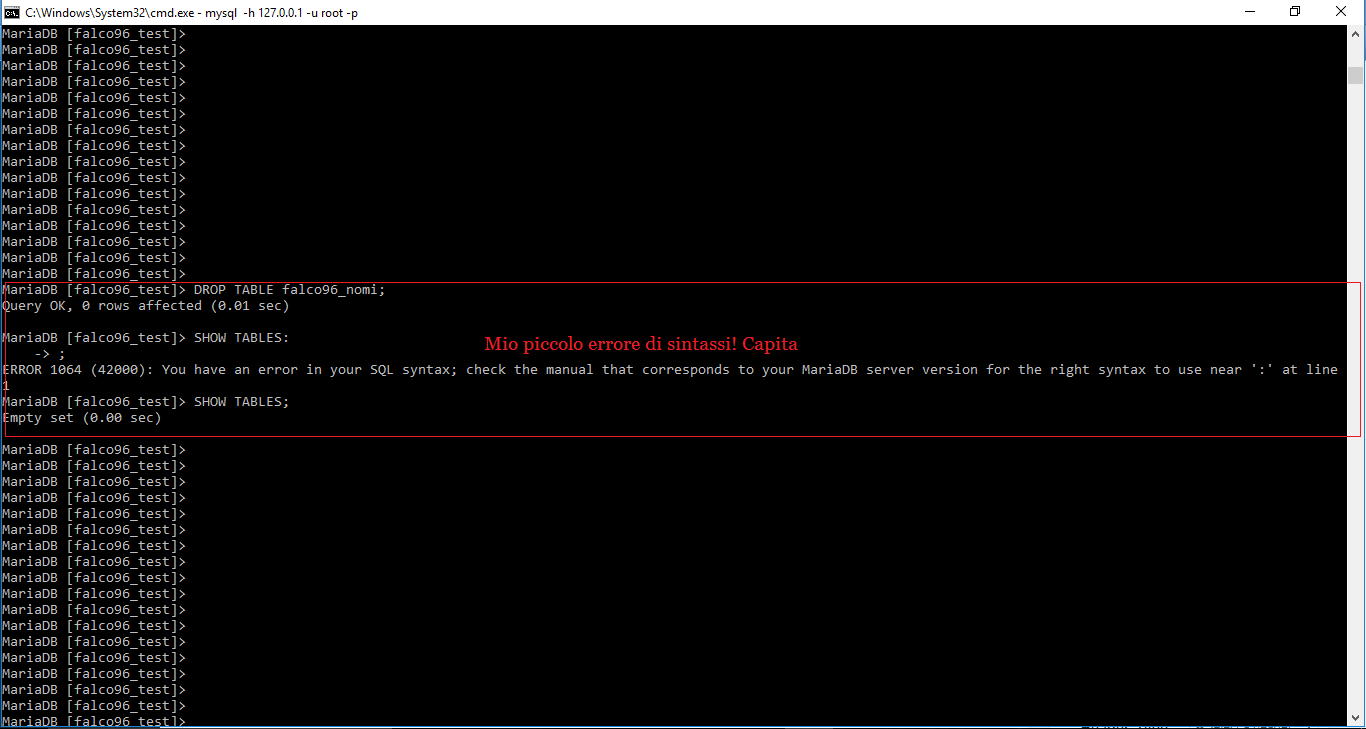
Ora non sono più presenti tabelle all’interno del database.
Facciamo un riepilogo di tutti i comandi che abbiamo visto oggi:
| TRUNCATE | DROP (DROP TABLE, DROP DATABASE) | ALTER TABLE (ADD, rename to) | DESCRIBE TABLE |
| SHOW (DATABASES, TABLES) | USE (riferito ai database) | INSERT | SELECT |
Penso che sia sufficiente per questo articolo 🙂 Abbiamo visto molte cose, praticamente le più importanti. Abbiamo visto come si gestisce un database a livello quasi avanzato. Già con le informazioni contenute qui dentro e che tu, arrivato qui in fondo, sicuramente avrai letto, sarai in grado di gestire un database quasi in modo completo.
Se invece vuoi approfondire qualche altro punto, beh non ti resta altro che aspettare l’uscita del prossimo articolo, che finiremo di vedere 2 cose.
Spero di non averti annoiato oggi. Lo so è lungo questo articolo da leggere, ma penso che ne sia valsa la pena.
Ciao a tutti e al prossimo articolo 🙂
{kind=link}